
Yatırım fonlarında yer alan hisselerin fon içerisindeki dağılımına ait bilgiyi hazır olarak bulmak güç. Fon yönetici şirketler belli periyotlarda KAP‘a fon dağılım raporlarını yayınamakta fakat bu raporları PDF formatında paylaştıkları için fonun hangi hisse senetlerine yatırım yaptığı bilgisini dinamik olarak alması pek mümkün olmuyor.
Bu bilgiyi veren firma, aracı kurum ya da web siteleri bulunmaktadır. Burada, anlikfon.com sitesinin https://anlikfon.com/hisselerin-fonlar-icindeki-dagilimlari sayfasını kullanacağız.
Gerekli Python kütüphaneleri
Bu örnek için kullanılan Python kütüphaneleri Requests, BeautifulSoup ve Pandas olacaktır. Öncelikle bu kütüphanelerin kurulması gerekiyor.
pip install requests
pip install BeautifulSoup
pip install pandasParametre ve değişkenleri tanımlama
Gerekli kütüphaneleri import ettikten ve sonuçların daha anlaşılır bir şekilde görüntülenmesine dair parametreleri ayrladıktan sonra web sayfasındaki veriyi içeren bağlantıyı tanımlayıp bu sayfa içeriğini sayfa adında bir değişkene atıyoruz.
import requests
from bs4 import BeautifulSoup
import pandas as pd
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.width', 1000)
URL = "https://anlikfon.com/hisselerin-fonlar-icindeki-dagilimlari"
page = requests.get(URL)
soup = BeautifulSoup(page.content, "html.parser")Sayfa içeriğini DataFrame’a aktarma
Bu içeriği, sadece ihtiyacımız olan tabloyu alacak şekilde düzenliyoruz.
- Nihai sonuçları atacağımız boş bir liste tanımlıyoruz.
- Sayfadaki fon ve hise verileri bir <table> etikeninin içinde yer alan <tr> tablo satırlarında yer alıyor. BeautifulSoup ile bu satırları bir döngü içine alıp ilgili bilgileri sırasıyla listemize ekliyoruz.
- Bu veride hem kolon adlarını içeren satır geliyor hem de fazladan bir satır geliyor. Bu örneği hazırladığım sırada ADESE için geliyordu bu fazla satır. Bu iki satırı listeden çıkarıp bu veriyi de liste adında yeni bir listeye atıyoruz.
- Kolon adlarını kendi istediğimiz şekilde yapmak isteyebiliriz. O yüzden ayrı bir liste halinde kolon adlarını tanımlıyoruz.
- Bu son listeyi de bir DataFrame içine atıyoruz. Son haliyle bu DF içinde yer alıyor veriler.
liste_0 = []
for table in soup.find_all("table", {"id": "example"}):
for tr in soup.find_all("tr"):
tr_content = tr.getText().replace("\n\n\n\n", "\n").replace("\n\n\n", "\n").replace("\n\n", "\n").split(chr(10))
liste_0.append([tr_content[1], tr_content[2], tr_content[3], tr_content[4], tr_content[5]])
# Kolon adları ve fazladan gelen bir satır çıkarılır
liste = liste_0[2:]
# Kolon adları yeniden tanımlanır
kolonlar = ["Hisse Kodu", "Hisse Adı", "Fon Sayısı", "Toplam Yüzde", "Fonlar"]
# Liste DF içine alınır
df_sayfa = pd.DataFrame(liste, columns = kolonlar)
df_sayfa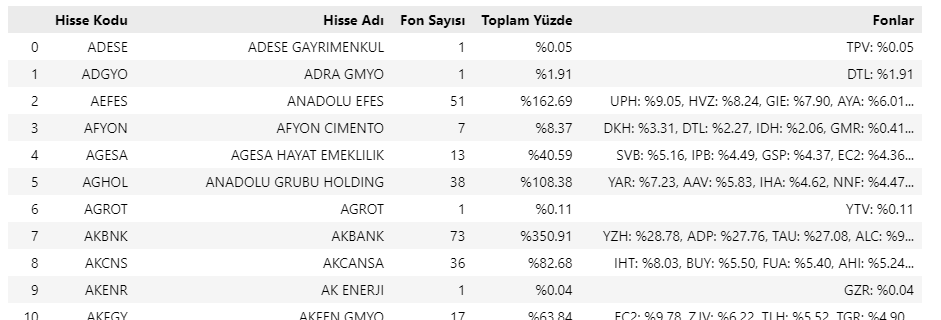
Hisse adına göre arama
Bu veri setinde hisse senedi adına göre arama yapmak istediğimizde bir liste içerisinde bu hisseleri tanımlayıp yeni bir DataFrame içine bu filtrelenmiş veriyi atıyoruz.
# Hisseler liste olarak tanımlanır
hisseler = ["KCHOL", "TUPRS"]
df_h = df_sayfa[df_sayfa["Hisse Kodu"].isin(hisseler)]
df_h

Fon adına göre arama
Benzer şekilde, bu hisselerin hangi fonlarda, hangi oranlarda yer aldığını bulmak için de yine bir liste içerisinde bu hisseleri tanımlayıp yeni bir DataFrame içine bu filtrelenmiş veriyi atıyoruz.
# Fon adları liste olarak tanımlanır
fonlar = ["YAS", "YZH"]
df_f = df_sayfa[df_sayfa["Fonlar"].str.contains(('|').join(fonlar))]
df_f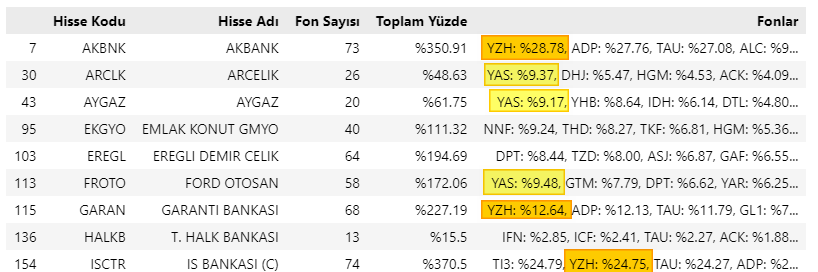
Dosya çıktısı – Excel
Dosyanın çıktısını da Excel olarak alıp bu ortamda da filtreleme yapabilirsiniz.
df_sayfa.to_excel("c:.../fon_hisse.xlsx", index=False)